
Most organisations are investing more in AI than ever before and getting less from it over time. Not because technology fails. Because of three structural decisions made even before the first model was built. Some organisations break that pattern. Their AI work successively takes less effort, delivers better results and compounds returns. Others spend similar amounts and plateau. This article explains what separates the two paths and what businesses can do to ensure AI value compounds.
How AI Can Build on Earlier Work
When AI programmes are set up well, each one tends to make the next one cheaper and faster. Earlier programmes produce useful outputs that later programmes can use – clean, well-organised data, shared technical components, and a better understanding of what works. A team that builds a sales forecasting model, for example, will go through the work of cleaning and standardising transaction data. If a later team wants to build a pricing model, they can start from that already-prepared data rather than starting from scratch. A model that identifies customers who might be about to leave generates detailed records of customer behaviour. A later team building a product recommendation system can use those records as a starting point. In each case, the earlier programme leaves something behind that has value beyond its immediate purpose.
When programmes are not structured this way, each one tends to start from scratch. Each team gathers and prepares data for those specific programmes, builds the model, and moves on. Individual programmes can still work well. But the organisation does not carry anything forward. After several years of AI investment, it may have a collection of working solutions but no shared infrastructure or knowledge that makes new programmes easier to start.

The underlying question is whether each new AI programme benefits from the work that came before it. If the answer is yes, the organisation’s AI capability tends to grow over time. If the answer is no, it tends to plateau.
1. Decisions Made Early Have a Long Reach
The decisions that most affect whether AI builds on itself over time are often not framed as AI decisions when they arise. They appear as questions about data management, team structure, or how to evaluate technology investment. Yet they have a significant effect on how AI projects progress over the following years.
- The first is who owns the data. In many organisations, each business unit manages its own data independently. This is a reasonable way to assign accountability, but it creates practical problems for AI.
When a new solution needs data from multiple parts of the enterprise, the team must negotiate access separately with each unit and often finds that the same concepts, a customer record, a product code, a transaction, have been defined differently in different systems. Models built on this kind of inconsistent data are harder to maintain and harder to connect to other models.
Organisations that set shared standards for how data is defined and organised, while keeping day-to-day data management within business units, tend to find that AI programmes are quicker to start and easier to update over time. Each programme adds to a shared pool of usable data rather than building its own isolated dataset.•
- The second is how success is measured. If each AI programme is evaluated on its own ROI, programmes that build shared infrastructure tend to look less attractive. The costs fall on the current programme’s budget, but much of the benefit goes to future programmes. This can lead teams to favour work that shows clear results quickly over work that helps the organisation over time. Tracking metrics across the entire AI portfolio, covering not just financial returns but also technical feasibility and commercial viability, provides a more accurate picture of progress. Useful indicators include how much data is in a shared usable format, how often components get reused across programmes, and how quickly new programmes reach deployment.

- The third is whether to buy ready-made AI tools or build on shared internal infrastructure. Buying off-the-shelf tools produces results faster in the short term, but the data and models stay inside the vendor’s system. The organisation builds no internal capability from the investment, and when the contract ends or needs change, there is little to build on. Organisations that invest in shared infrastructure first tend to find that later programmes are cheaper and faster to deliver, because the foundation is reused rather than rebuilt.
One way to surface answers before committing to a direction is through a structured, Rapid prototyping process. Not a full pilot, but a focused innovation and validation exercise designed to test whether a specific use case has the data readiness, business ownership, and production pathway it needs. The goal is not to produce a working model. It is to find out, in a few weeks, which of the three decisions above have clear answers and which do not. A prototype that surfaces ambiguity early costs very little. Discovering it after several months of data foundation work is substantially more expensive.
2. Data Foundations and How Teams are Organised
A data foundation is the set of shared data assets and standards that AI solutions draw from. It typically includes a taxonomy of agreed definitions of core business concepts used consistently across the organisation: what counts as a customer, a product, a transaction; data quality standards applied at the point of collection rather than later; a shared library of pre-calculated measures such as average order value or days since last purchase, reusable across multiple models; and data lineage – records of where data came from, how it has moved, and how it has changed over time, so that models can be updated reliably as the underlying data evolves.
Building a data foundation can take up several months and does not produce direct financial returns during that time. This makes it difficult to justify under standard annual budget processes. As a result, many organisations skip this step and invest directly in building models. The models work, but they are built on data that has been defined and collected differently in different parts of the organisation, which makes them harder to maintain and connect.

How AI teams are organised also affects how well the organisation accumulates capability over time. A common arrangement is a central AI & data science team that takes requests from different parts of the business, builds models, and hands them back. This is simple to manage, but it tends to create a queue of requests, and the models produced may not quite fit the way the business works, because the people with the most relevant business knowledge are not closely involved in building them.
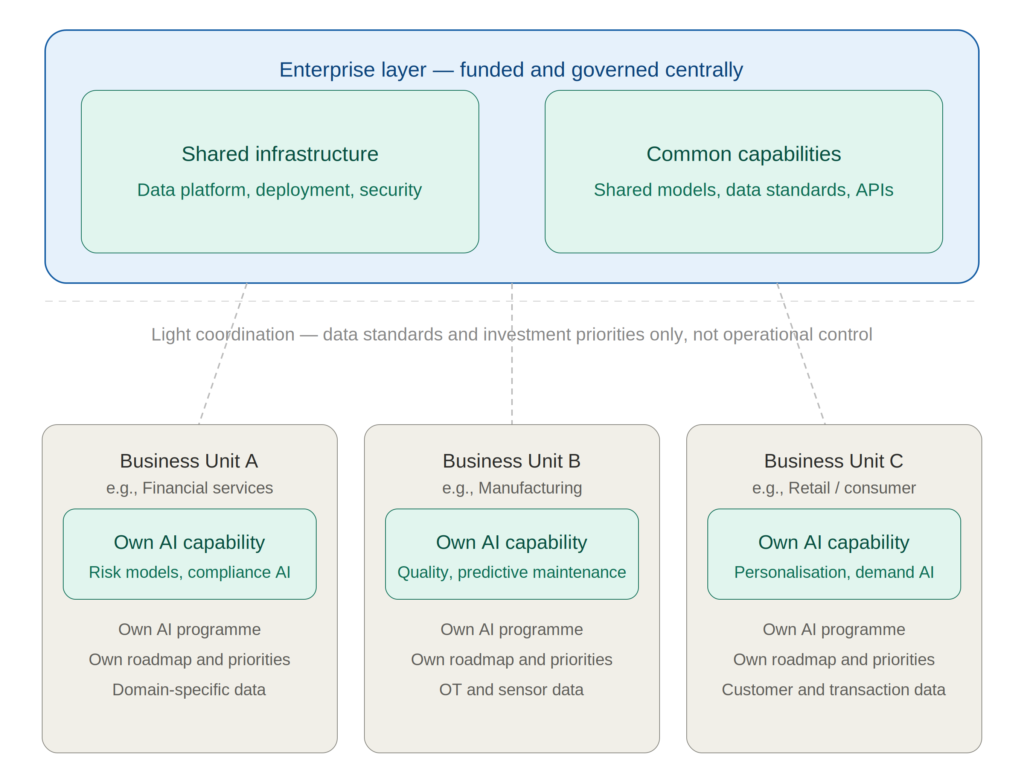
A more effective arrangement, which several larger organisations have moved towards, is to keep shared infrastructure – the data foundation, the model deployment platform, data standards managed centrally, while embedding AI capability within each business unit for day-to-day work. This means the people building models have direct knowledge of the business context, while still being able to draw on shared resources. It is more complex to coordinate, but it tends to produce models that are better suited to how the business operates and that reach active use more quickly.
Organisations don’t have to commit to a full data foundation before they know where to build it. A more useful sequence is to run a small number of rapid prototypes first – does this use case have the data, the ownership, and the production pathway to be worth a foundation investment? The prototype answers that question quickly and cheaply.
The answer then tells the organisation which parts of the data foundation to build first, in what order, and for which use cases. This makes the longer-term investment more targeted and easier to justify.
3. The Cost of AI Fragmentation
Most large organisations are running several AI programmes simultaneously, often started independently by different teams. A digital team might be working on product recommendations, a supply chain team building a demand forecast, a finance team using a purchased prediction tool, and an HR team using a recruitment screening system.
A problem that often emerges is that these programmes do not connect to each other.
A practical question about ownership
“When an AI solution is deployed, who is responsible for whether it delivers value: the team that built it, or the team using it? If responsibility sits mainly with builders, solutions get handed over and stop being maintained. If it sits mainly with users, they have no incentive to invest in shared capabilities. Arrangements that work make both sides jointly accountable, with the data infrastructure team included.”
The supply chain team’s demand forecast may use a definition of ‘product’ from the digital team’s recommendation system. The recruitment screening tool may handle applicant data under legal restrictions that prevent it from being used in other HR systems. The finance team’s prediction tool may run on vendor infrastructure and produce outputs that cannot feed into the organisation’s planning system. Each programme works in isolation, but the organisation cannot combine or build on them.
The cost of this kind of fragmentation is significant. Organisations running AI programmes in parallel without shared infrastructure tend to solve the same infrastructure problems repeatedly. The scale of what this cost is better documented than most organisations realise. Gartner predicts that 60% of AI projects without AI-ready data will be abandoned, with poor data quality cited as the primary cause in both cases. Forrester identifies the same root: fragmented data pipelines and absent governance are what turn promising pilots into expensive write-offs.
4. Ownership and Shared Investment
The most common reason AI investment stays fragmented is practical: the teams that bear the cost of building shared capabilities are not the teams that benefit from it. If each team is assessed on its own results, the rational choice is to solve its own problems rather than invest in resources that help others.
Organisations that have made progress on this tend to fund shared infrastructure centrally rather than charging it to a specific team’s budget and review the AI portfolio at a senior level rather than by programmes.
In organisations with multiple business units, this problem operates at two levels. Within each unit, teams need incentives to build shared capabilities rather than isolated solutions. Across units, there are assets that would benefit the whole group, a unified customer view, shared supply chain data, a common deployment platform, but that no individual unit would fund alone. Without governance that makes these investments worthwhile for the unit bearing the cost, each unit builds its own version.
Groups that have solved this tend to have a small coordination layer: agreed data standards, a team responsible for shared infrastructure, and a deployment platform units can use without building their own. Each unit keeps full control of its own AI programme. The coordination layer provides tools and sets standards; it does not direct what units build.
From AI Pilots to a Compounding Portfolio
The real point is what the portfolio delivers. Cheaper and faster models that do not move revenue, reduce cost, or improve decisions are still a poor investment. The only measure that matters is the business value the AI programme creates, for customers, for operations, for the organisation as a whole.
The organisations that will lead AI over the next five years are already running the governance programmes their competitors will need three years from now.
For enterprises, the immediate opportunity is to shift from successful individual AI initiatives to a compounding portfolio. That means agreeing group-wide definitions for core data, funding shared foundations (data standards, reusable components and a common deployment pathway) centrally, and using rapid prototypes to confirm data readiness and business ownership before scaling. Done well, each new use case leaves behind assets the next one can reuse; reducing delivery time, improving maintainability, and ensuring AI investment grows in value rather than fragmenting across business units.
Author: Swarup Kar, AI Consultant

